Labeling of Measurements and Label Propagation
MVG comes with a labeling API that allows a user to store important information about a measurement. There are multiple reasons why you would want to label measurements and some of the benefits include:
Additional information about modes. For example, a mode with multiple critical measurements is likely a failure mode.
Improved mode detection.
As personal notes for keeping track of interesting events in the data.
In addition, the LabelPropagation feature enables to propagate those labels to the measurements that do not contain any labels.
This example will go through what a label is in MVG, how the labeling API functions, and how to utilize the LabelPropagation feature.
Prerequisites
To follow this example you need to have:
Installed
mvgpackageA token for API access from Viking Analytics
The database needs to be populated with our example assets. This can be achieved by running the “Sources and Measurement” example.
Use of the LabelPropagation feature requires the results from ModeId. We can use the results available after running the “Analysis and Results Visualization” example.
Import the required packages and functions
[1]:
import os
from mvg import MVG
from mvg.analysis_classes import parse_results
from mvg.plotting import plot_labels_over_time
Create a session for API access
Note
Each token is used for Authorization AND Authentication. Thus, each unique token represents a unique user, each user has it own, unique database on the VA-MVG’ service.
You need to insert your token received from Viking Analytics here: Just replace "os.environ['TEST_TOKEN']" by your token as a string.
[2]:
TOKEN = os.environ["TEST_TOKEN"]
ENDPOINT = "https://api.beta.multiviz.com"
[3]:
session = MVG(ENDPOINT, TOKEN)
session.check_version()
[3]:
{'api_version': '0.4.0',
'mvg_highest_tested_version': '0.4.0',
'mvg_version': '0.13.0'}
Retrieve ModeId results
Once the API session is live, we start by checking if the source u0001 we will use is available in the database.
[4]:
SOURCE_ID = "u0001"
session.get_source(SOURCE_ID)
[4]:
{'source_id': 'u0001',
'meta': {'assetId': 'assetA',
'measPoint': 'mloc01',
'location': 'paris',
'updated': 'YES! I have been updated'},
'properties': {'data_class': 'waveform', 'channels': ['acc']}}
Now that we know that the source exists we need to check its measurements to know which ones to label.
In this example, the ModeId results are used to select the measurements to label and to compare with the results from the LabelPropagation feature. The ModeId results are NOT needed to add a label to the measurements.
[5]:
ModeId_request_id = session.list_analyses(sid=SOURCE_ID, feature="ModeId")[-1]
raw_result = session.get_analysis_results(ModeId_request_id)
result = parse_results(raw_result, "Europe/Stockholm", "s")
u0001_df = result.to_df()
u0001_df.head()
[5]:
| datetime | timestamps | labels | uncertain | mode_probability | |
|---|---|---|---|---|---|
| 0 | 2019-10-05 13:01:00+02:00 | 1570273260 | 0 | False | 0.966994 |
| 1 | 2019-10-06 13:01:00+02:00 | 1570359660 | 0 | False | 0.931219 |
| 2 | 2019-10-07 13:01:00+02:00 | 1570446060 | 0 | False | 0.999575 |
| 3 | 2019-10-08 13:01:00+02:00 | 1570532460 | 0 | False | 0.979806 |
| 4 | 2019-10-09 13:01:00+02:00 | 1570618860 | 0 | False | 0.885940 |
[6]:
result.plot()

[6]:
''
Adding labels
A label in MVG relates to a specific measurement, which are identifiable by the source ID and the timestamp. Each measurement can only have one label. The label itself has three components:
A label identification string
A severity level number
Notes
Note
The label identification string is unique for each label and is case and spelling sensitive, i.e. "failure" and "Failure" are not interpreted as the same label. The severity level is an integer where a larger number indicates a more severe problem. They do not need to be the same for different instances of the same label. The notes exist for the end user to add extra information to a certain label and is not used by MVG in any way.
For this example, let us say that there was a bearing failure of the machine in the first measurement of the source, so we will add a label to the afflicted measurements. To do so, we use the MVG.create_label() method.
[7]:
first_measurement = 1570273260
session.create_label(
sid=SOURCE_ID,
timestamp=1570273260,
label="bearing_failure",
severity=3,
notes="Imaginary bearing failure"
)
We just added one label to one of the measurements of the source. However, just one label for the entire source might not be enough especially if the modeId results show more than one mode. Therefore, it might be a good idea to add more labels. Thus, we proceed to attach a label to the top 3 measurements with the largest mode probability of mode from the ModeId feature results. First, we create a dataframe to identify these measurements.
[8]:
Top3meas_df = u0001_df[u0001_df.groupby('labels')['mode_probability'].rank(method='dense', ascending=False) <= 3]
Top3meas_df
[8]:
| datetime | timestamps | labels | uncertain | mode_probability | |
|---|---|---|---|---|---|
| 2 | 2019-10-07 13:01:00+02:00 | 1570446060 | 0 | False | 0.999575 |
| 7 | 2019-10-12 13:01:00+02:00 | 1570878060 | 0 | False | 0.996115 |
| 8 | 2019-10-13 13:01:00+02:00 | 1570964460 | 0 | False | 0.980702 |
| 17 | 2019-10-22 13:01:00+02:00 | 1571742060 | 1 | False | 0.996703 |
| 22 | 2019-10-27 13:01:00+01:00 | 1572177660 | 1 | False | 0.996604 |
| 23 | 2019-10-28 13:01:00+01:00 | 1572264060 | 1 | False | 0.996323 |
| 32 | 2019-11-06 13:01:00+01:00 | 1573041660 | 2 | False | 0.999899 |
| 36 | 2019-11-10 13:01:00+01:00 | 1573387260 | 2 | False | 0.999897 |
| 39 | 2019-11-13 13:01:00+01:00 | 1573646460 | 2 | False | 0.999187 |
There are three modes on the ModeId results. We will label measurements from mode 0 as “Healthy”, measurements from mode 1 as “Transition”, measurements from mode 2 as “Faulty”.
[9]:
modes = Top3meas_df['labels'].unique()
mode_dfs = {mode: Top3meas_df[Top3meas_df['labels'] == mode] for mode in modes}
for mode in mode_dfs:
if mode == 0:
label_to_add = "Healthy"
elif mode == 1:
label_to_add = "Transition"
else:
label_to_add = "Faulty"
case_df = mode_dfs[mode]
for index, row in case_df.iterrows():
session.create_label(
sid=SOURCE_ID,
timestamp=row['timestamps'],
label=label_to_add,
severity=int(mode)+1,
notes="This is a demo."
)
Reading Labels
To get a list of all the labels for a source we use the MVG.list_labels() method.
[10]:
session.list_labels(SOURCE_ID)
[10]:
{'timestamp': [1570273260,
1570446060,
1570878060,
1570964460,
1571742060,
1572177660,
1572264060,
1573041660,
1573387260,
1573646460],
'label': ['bearing_failure',
'Healthy',
'Healthy',
'Healthy',
'Transition',
'Transition',
'Transition',
'Faulty',
'Faulty',
'Faulty'],
'severity': [3, 1, 1, 1, 2, 2, 2, 3, 3, 3],
'notes': ['Imaginary bearing failure',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.'],
'label_timestamp': ['2022-05-10 10:15:56',
'2022-05-10 10:15:56',
'2022-05-10 10:15:56',
'2022-05-10 10:15:56',
'2022-05-10 10:15:56',
'2022-05-10 10:15:57',
'2022-05-10 10:15:57',
'2022-05-10 10:15:57',
'2022-05-10 10:15:57',
'2022-05-10 10:15:57']}
As you can see, the measurements that we just added labels show up. To inspect the label of a specific measurement we use MVG.get_label()
[11]:
session.get_label(SOURCE_ID, first_measurement)
[11]:
{'label': 'bearing_failure',
'severity': 3,
'notes': 'Imaginary bearing failure',
'label_timestamp': '2022-05-10 10:15:56'}
Updating labels
Now we realize that the label we had in the first measurement correspond to mode 0 and the label that we originally added is incorrect. Then we use the session.update_label() method to change the label.
[12]:
session.update_label(
sid=SOURCE_ID,
timestamp=first_measurement,
label="healthy",
severity=0,
notes="This was an OK measurement"
)
# List the labels again
labels = session.list_labels(SOURCE_ID)
labels
[12]:
{'timestamp': [1570273260,
1570446060,
1570878060,
1570964460,
1571742060,
1572177660,
1572264060,
1573041660,
1573387260,
1573646460],
'label': ['healthy',
'Healthy',
'Healthy',
'Healthy',
'Transition',
'Transition',
'Transition',
'Faulty',
'Faulty',
'Faulty'],
'severity': [0, 1, 1, 1, 2, 2, 2, 3, 3, 3],
'notes': ['This was an OK measurement',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.',
'This is a demo.'],
'label_timestamp': ['2022-05-10 10:15:56',
'2022-05-10 10:15:56',
'2022-05-10 10:15:56',
'2022-05-10 10:15:56',
'2022-05-10 10:15:56',
'2022-05-10 10:15:57',
'2022-05-10 10:15:57',
'2022-05-10 10:15:57',
'2022-05-10 10:15:57',
'2022-05-10 10:15:57']}
Plotting labels
To get an overview of the data and labels it can be very good to plot the labels over time. The plotting module of mvg contains the function plot_labels_over_time that does just that. The plot is very similar to that of the ModeId plots, so it is easy to compare results. We can add the include_unlabeled=True keyword to plot the unlabeled measurements as well. Please note how “healthy” and “Healthy” was interpreted as two different labels.
[13]:
labels = session.list_labels(SOURCE_ID, include_unlabeled=True)
plot_labels_over_time(labels, SOURCE_ID, timeunit="s")
[13]:
[]

As you can see we only labeled a small subset of the data. The idea is not to label all the measurements, but to label a part and then use that information to make inference about the unlabeled measurements.
Deleting labels
Now, we check the total number of existing labels in our source.
[14]:
labels = session.list_labels(SOURCE_ID)
print(f"Currently, there are {len(labels)} labels")
Currently, there are 5 labels
To delete labels we use the MVG.delete_label() method. Let’s use that to remove the label from the first measurement and keep only three labels per mode.
[15]:
session.delete_label(SOURCE_ID, first_measurement)
[16]:
labels = session.list_labels(SOURCE_ID)
print(f"Currently, there are {len(labels)} labels")
Currently, there are 5 labels
Label Propagation
Until this point, we had added labels to some of our measurements but we might be interested on adding the labels to the rest of the measurements. We use the “LabelPropagation” feature to achieve this.
The LabelPropagation feature uses the results from the ModeId feature to propagate the labels. However, the labels are attached to each measurement individually and not to the modes as a whole.
To use the LabelPropagation feature, we need to know which source is to be used and the request_id that holds the results of the ModeId feature. Then, we can request the analysis.
[17]:
params = {"model_ref": ModeId_request_id}
labelProp_u0001 = session.request_analysis(SOURCE_ID, "LabelPropagation", params)
labelProp_request_id = labelProp_u0001["request_id"]
labelProp_u0001
[17]:
{'request_id': 'e28ef3d9560bb88b5b70db685b8b8d8b', 'request_status': 'queued'}
We check the status of the analysis to ensure the analysis is finished.
[18]:
session.wait_for_analyses([labelProp_request_id])
out_status = session.get_analysis_status(labelProp_request_id)
out_status
[18]:
'successful'
Before we are able to get the analysis results, we need to wait until those analyses are successfully completed. Once the analysis is complete, one gets the results by calling the corresponding “request_id” for the LabelPropagation analysis. The raw results can be retrieved by calling the get_analysis_results function.
[19]:
labelprop_output = session.get_analysis_results(request_id=labelProp_request_id)
labelprop_output.keys()
[19]:
dict_keys(['status', 'request_id', 'feature', 'results', 'inputs', 'error_info', 'debug_info'])
The output is a dictionary that contains seven key elements. These elements are:
"status"indicates if the analysis was successful."request_id"is the identifier of the requested analysis."feature"is the name of the request feature."results"includes the numeric results."inputs"includes the input information for the request analysis."error_info"includes the error information in case the analysis fails and it is empty if the analysis is successful."debug_info"includes debugging (log) information related to the failed analysis.
To make the results more accessible, we’ll use the analysis_classes. The parse_results function will take the raw_results of (any) analysis and represent them in a python object with a number of convenience methods for plotting and exporting. The parse function will automatically determine the kind (feature) of analysis based on the raw_results and based on the defined timezone convert the epoch into actual dates.
[20]:
labelprop_results = parse_results(labelprop_output, "Europe/Stockholm", "s")
Once we had parsed the results, we can export them to a dataframe for ease of manipulation
[21]:
labelprop_results.to_df()
[21]:
| label | severity | notes | label_timestamp | datetime | timestamp | certainty_level | |
|---|---|---|---|---|---|---|---|
| 0 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-05 13:01:00+02:00 | 1570273260 | 1.0 |
| 1 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-06 13:01:00+02:00 | 1570359660 | 1.0 |
| 2 | Healthy | 1 | This is a demo. | 2022-05-10 10:15:56 | 2019-10-07 13:01:00+02:00 | 1570446060 | 1.0 |
| 3 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-08 13:01:00+02:00 | 1570532460 | 1.0 |
| 4 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-09 13:01:00+02:00 | 1570618860 | 1.0 |
| 5 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-10 13:01:00+02:00 | 1570705260 | 1.0 |
| 6 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-11 13:01:00+02:00 | 1570791660 | 1.0 |
| 7 | Healthy | 1 | This is a demo. | 2022-05-10 10:15:56 | 2019-10-12 13:01:00+02:00 | 1570878060 | 1.0 |
| 8 | Healthy | 1 | This is a demo. | 2022-05-10 10:15:56 | 2019-10-13 13:01:00+02:00 | 1570964460 | 1.0 |
| 9 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-14 13:01:00+02:00 | 1571050860 | 1.0 |
| 10 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-15 13:01:00+02:00 | 1571137260 | 1.0 |
| 11 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-16 13:01:00+02:00 | 1571223660 | 1.0 |
| 12 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-17 13:01:00+02:00 | 1571310060 | 1.0 |
| 13 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-18 13:01:00+02:00 | 1571396460 | 1.0 |
| 14 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-19 13:01:00+02:00 | 1571482860 | 1.0 |
| 15 | Healthy | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-20 13:01:00+02:00 | 1571569260 | 1.0 |
| 16 | Transition | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-21 13:01:00+02:00 | 1571655660 | 1.0 |
| 17 | Transition | 2 | This is a demo. | 2022-05-10 10:15:56 | 2019-10-22 13:01:00+02:00 | 1571742060 | 1.0 |
| 18 | Transition | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-23 13:01:00+02:00 | 1571828460 | 1.0 |
| 19 | Transition | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-24 13:01:00+02:00 | 1571914860 | 1.0 |
| 20 | Transition | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-25 13:01:00+02:00 | 1572001260 | 1.0 |
| 21 | Transition | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-26 13:01:00+02:00 | 1572087660 | 1.0 |
| 22 | Transition | 2 | This is a demo. | 2022-05-10 10:15:57 | 2019-10-27 13:01:00+01:00 | 1572177660 | 1.0 |
| 23 | Transition | 2 | This is a demo. | 2022-05-10 10:15:57 | 2019-10-28 13:01:00+01:00 | 1572264060 | 1.0 |
| 24 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-29 13:01:00+01:00 | 1572350460 | 1.0 |
| 25 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-30 13:01:00+01:00 | 1572436860 | 1.0 |
| 26 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-10-31 13:01:00+01:00 | 1572523260 | 1.0 |
| 27 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-01 13:01:00+01:00 | 1572609660 | 1.0 |
| 28 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-02 13:01:00+01:00 | 1572696060 | 1.0 |
| 29 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-03 13:01:00+01:00 | 1572782460 | 1.0 |
| 30 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-04 13:01:00+01:00 | 1572868860 | 1.0 |
| 31 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-05 13:01:00+01:00 | 1572955260 | 1.0 |
| 32 | Faulty | 3 | This is a demo. | 2022-05-10 10:15:57 | 2019-11-06 13:01:00+01:00 | 1573041660 | 1.0 |
| 33 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-07 13:01:00+01:00 | 1573128060 | 1.0 |
| 34 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-08 13:01:00+01:00 | 1573214460 | 1.0 |
| 35 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-09 13:01:00+01:00 | 1573300860 | 1.0 |
| 36 | Faulty | 3 | This is a demo. | 2022-05-10 10:15:57 | 2019-11-10 13:01:00+01:00 | 1573387260 | 1.0 |
| 37 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-11 13:01:00+01:00 | 1573473660 | 1.0 |
| 38 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-12 13:01:00+01:00 | 1573560060 | 1.0 |
| 39 | Faulty | 3 | This is a demo. | 2022-05-10 10:15:57 | 2019-11-13 13:01:00+01:00 | 1573646460 | 1.0 |
| 40 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-14 13:01:00+01:00 | 1573732860 | 1.0 |
| 41 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-15 13:01:00+01:00 | 1573819260 | 1.0 |
| 42 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-16 13:01:00+01:00 | 1573905660 | 1.0 |
| 43 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-17 13:01:00+01:00 | 1573992060 | 1.0 |
| 44 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-18 13:01:00+01:00 | 1574078460 | 1.0 |
| 45 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-19 13:01:00+01:00 | 1574164860 | 1.0 |
| 46 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-20 13:01:00+01:00 | 1574251260 | 1.0 |
| 47 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-21 13:01:00+01:00 | 1574337660 | 1.0 |
| 48 | Faulty | -1 | Added by label propagation | 2022-05-10 10:16:12 | 2019-11-22 13:01:00+01:00 | 1574424060 | 1.0 |
We can also display the results and visualize the labels given to the different measurements.
[22]:
labelprop_results.plot()
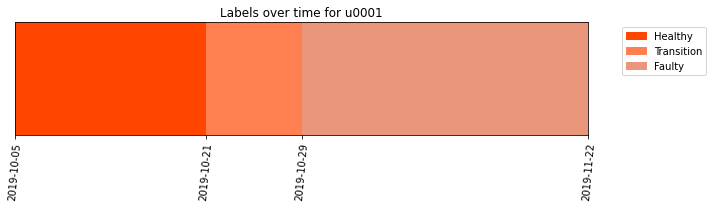
[22]:
''
As you can see from the results, it is easier to appreciate now which measurements have a healthy behavior, which measurements have a faulty behavior and which measurements have a transition behavior from healthy to faulty.